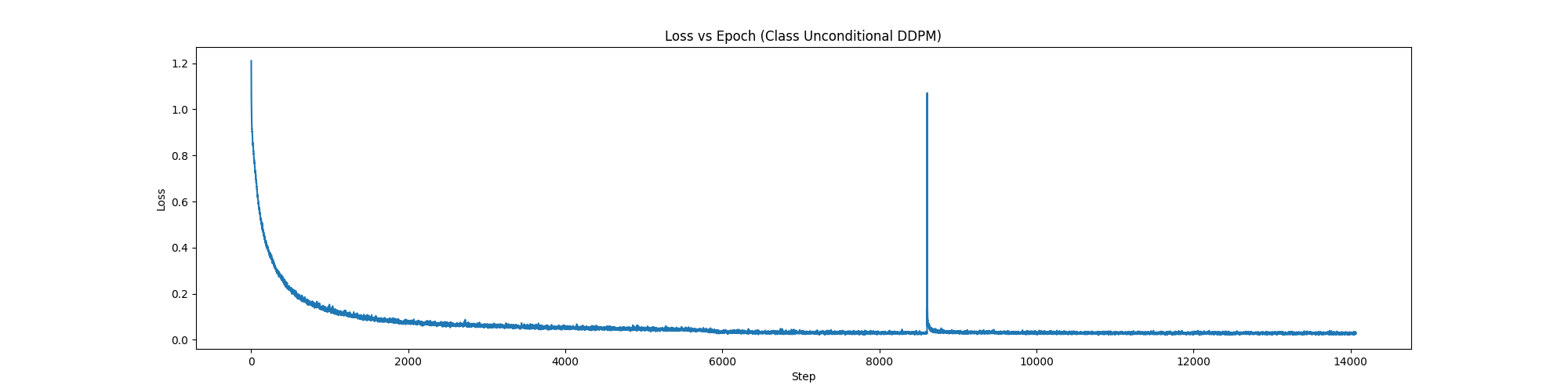
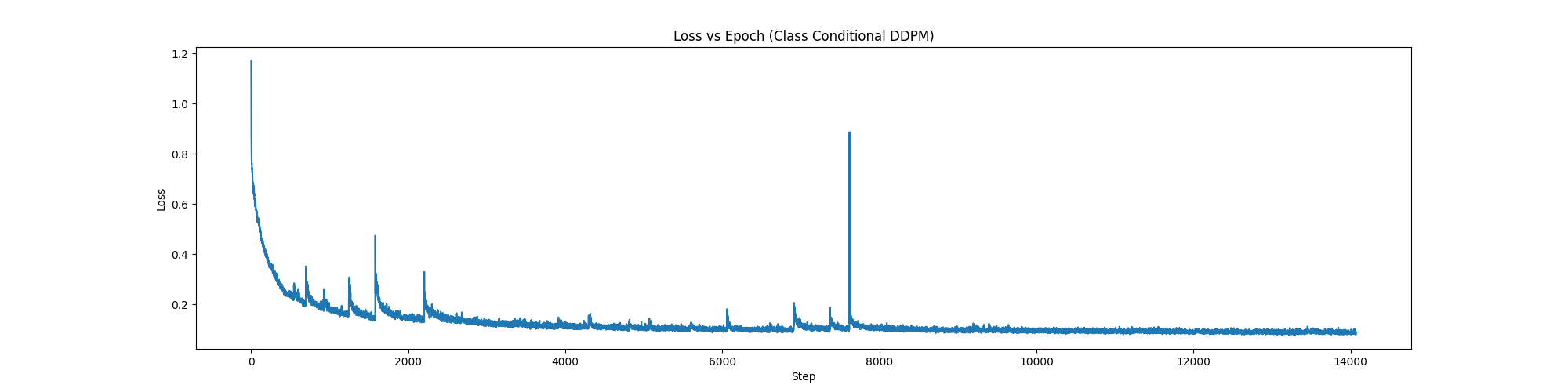
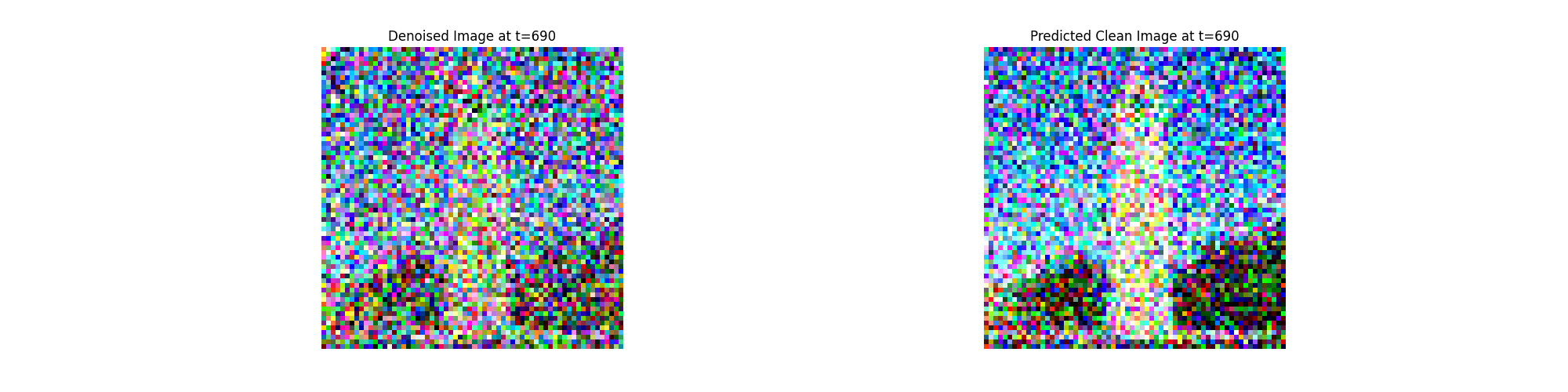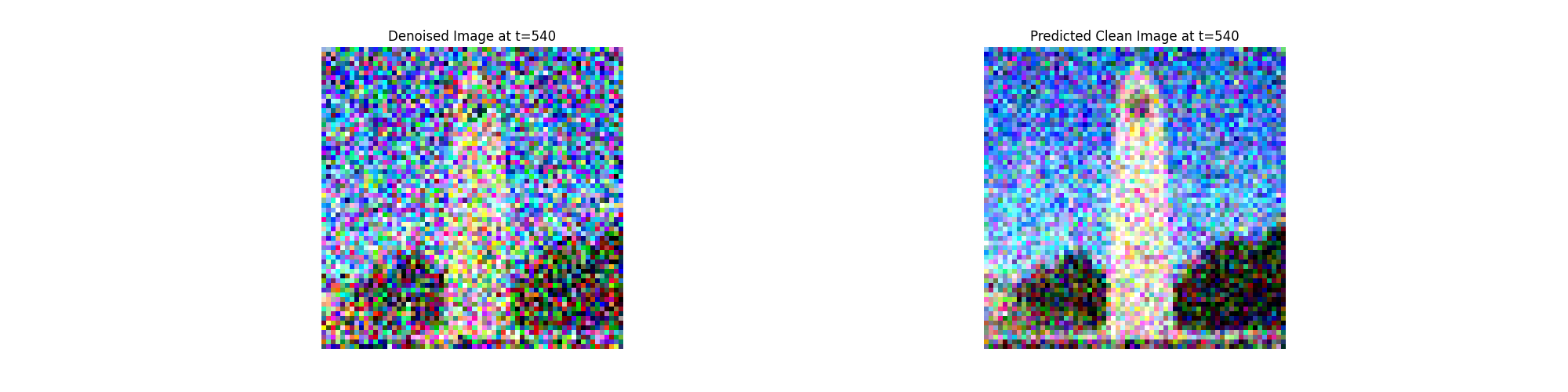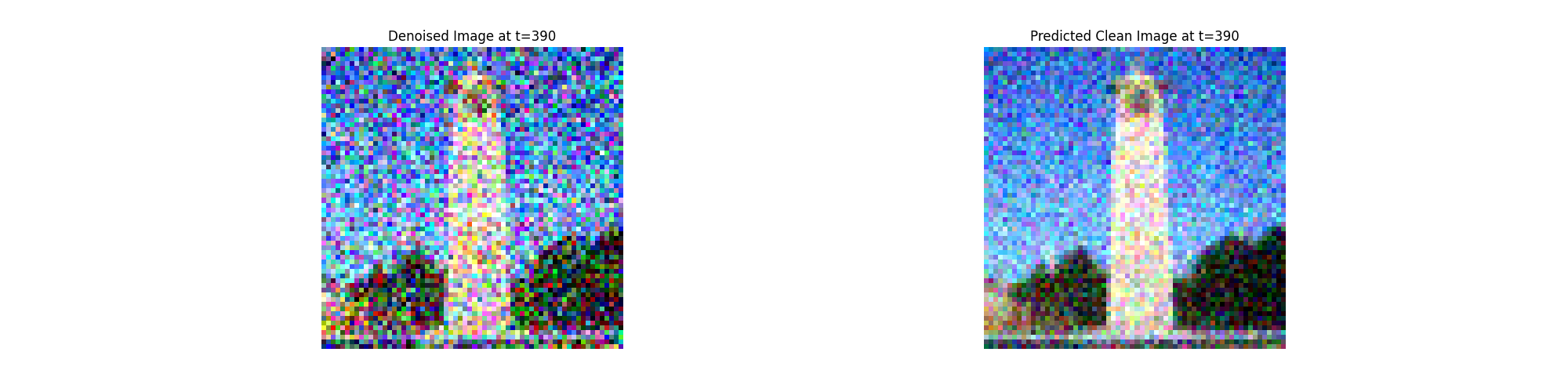1.4 Implementing Iterative Denoising¶
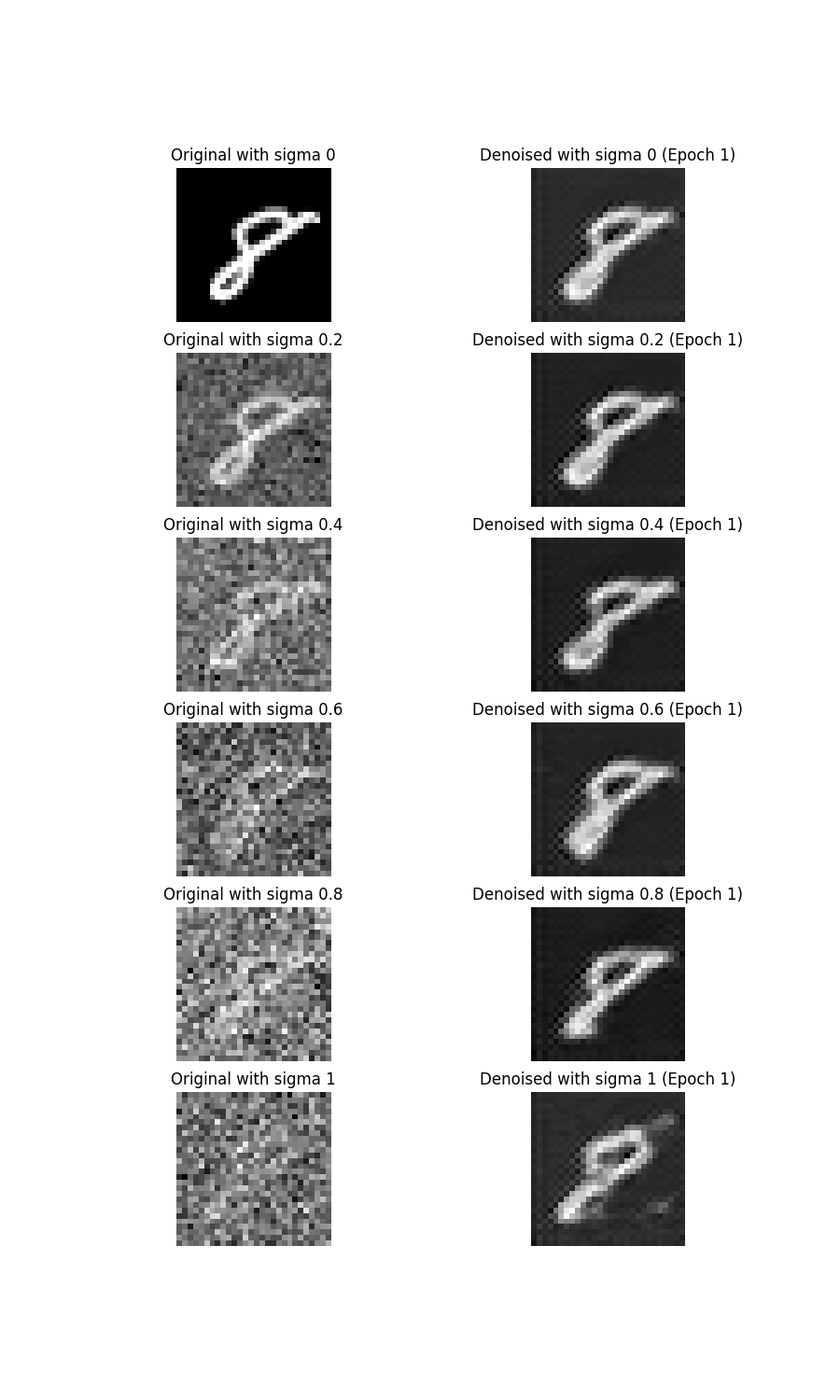
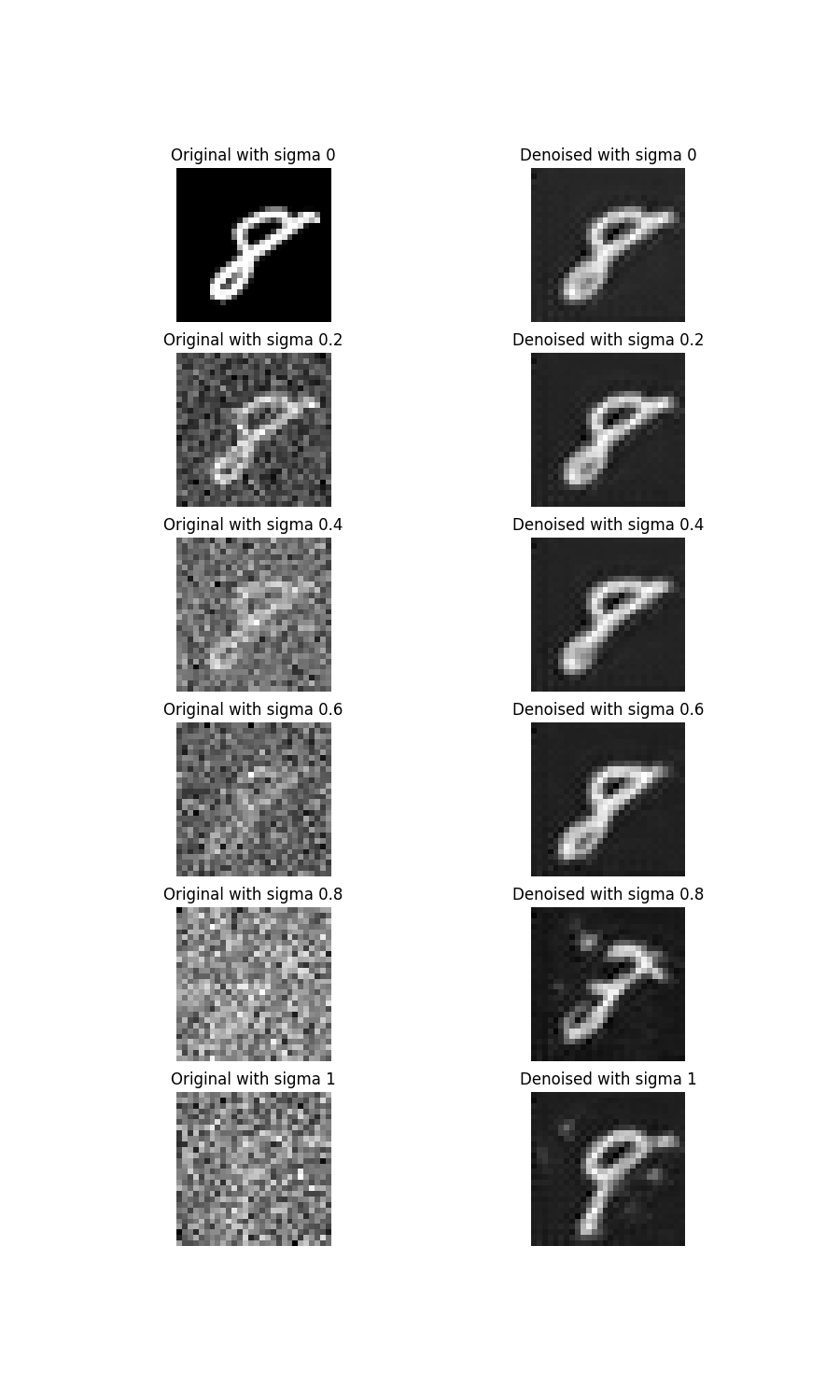
In part 1.3, you should see that the denoising UNet does a much
better job of projecting the image onto the natural image
manifold, but it does get worse as you add more noise. This makes
sense, as the problem is much harder with more noise!
But diffusion models are designed to denoise iteratively. In this
part we will implement this.
In theory, we could start with noise $x_{1000}$ at timestep
$T=1000$, denoise for one step to get an estimate of $x_{999}$,
and carry on until we get $x_0$. But this would require running
the diffusion model 1000 times, which is quite slow (and costs
$$$).
It turns out, we can actually speed things up by skipping steps.
The rationale for why this is possible is due to a connection with
differential equations. It's a tad complicated, and out of scope
for this course, but if you're interested you can check out
this excellent article.
To skip steps we can create a list of timesteps that we'll call
strided_timesteps, which will be much shorter than
the full list of 1000 timesteps.
strided_timesteps[0] will correspond to the noisiest
image (and thus the largest $t$) and
strided_timesteps[-1] will correspond to a clean
image (and thus $t = 0$). One simple way of constructing this list
is by introducing a regular stride step (e.g. stride of 30 works
well).
On the ith denoising step we are at $ t = $
strided_timesteps[i], and want to get to $ t' =$
strided_timesteps[i+1] (from more noisy to less
noisy). To actually do this, we have the following formula:
$ x_{t'} = \frac{\sqrt{\bar\alpha_{t'}}\beta_t}{1 - \bar\alpha_t}
x_0 + \frac{\sqrt{\alpha_t}(1 - \bar\alpha_{t'})}{1 -
\bar\alpha_t} x_t + v_\sigma$
where:
- $x_t$ is your image at timestep $t$
-
$x_{t'}$ is your noisy image at timestep $t'$ where $t' < t$
(less noisy)
-
$\bar\alpha_t$ is defined by
alphas_cumprod, as
explained above.
- $\alpha_t = \bar\alpha_t / \bar\alpha_{t'}$
- $\beta_t = 1 - \alpha_t$
-
$x_0$ is our current estimate of the clean image using equation
2 just like in section 1.3
The $v_\sigma$ is random noise, which in the case of DeepFloyd is
also predicted. The process to compute this is not very important
for us, so we supply a function, add_variance, to do
this for you.
You can think of this as a linear interpolation between the signal
and noise: